| Меню сайта |
|
 |
| Категории раздела |
|
|
| Мини-чат |
|
|
|
| Наш опрос |
|
|
| Статистика |
Онлайн всего: 1 Гостей: 1 Пользователей: 0 |
|
| Форма входа |
|
|
|
 |  |  |  |
 | Главная » 2009 » Октябрь » 28 » Как сделать из PDF «нормальный» текст
03:52 Как сделать из PDF «нормальный» текст |
По горячим следам.
Краткий список шагов.
Если PDF в виде картинки, то надо эти картинки вытащить
- xPDF или Some PDF Images
- Может случиться такая неприятность, что на каждой странице будут разрозненные изображения. Тогда надо отрендерить страницу полностью чем-то другим
Я в итоге воспользовался ghostscript
gswin32c.exe -dSAFER -dBATCH -dNOPAUSE -sDEVICE=png16m -r400 -sOutputFile=output%04d.p>ng input.pdf
Вот такая комманда сделает из pdf файла отдельные png-картинки с качеством 400pdi
- Тут дальше идет чистка по желанию, обрезка колонтитулов и прочее
Если у страниц разная степень заливки текстом, то иногда будет полезно наложить все страницы друг на друга, чтобы посмотреть где имено надо обрезать лишне.
Опять таки мне помог консольный ImageMagick
convert *.png -compose darken -flatten out.jpg
Если PDF с текстом, то можно попытаться его вытащить. Бесплатных программ найдено не было, но из платных Solid PDF Converter умеет всё и делает это отлично. Правда я заметил, что он плохо дружет с символами переноса, считая из дефисами. Да и с колонтитулами и прочим мусором придется разбираться отдельно.
Можно текстовый PDF перевести в картинки той же командой ghostscript и задача сводится к предыдущей.
Теперь FineReader. Если скан чистый и без колонтитулов, то задача очень проста. Следует только позаботиться о двух вещах:
- вручную выделить картинки (после того как он разобьет на блоки автоматом)
- блоки на страницах на которых есть колонки, надо выделить в порядке вниз-вправо, а то потом они перемешаются в неправильном порядке
FineReader 10 показывают удивительную точность распознования текста. На страницу из 300 книг было найден всего десяток неправильных символов (это то, что подсвечивает Word)
А теперь нам нужен OpenOffice. Не сколько он сам, а мега-плагин OOoFBTools.
Он нам нужен по двум причинам:
Почистить текст (OOoFBTools -> Корректор текста)
Разметить текст и сделать FB2 книгу
После установки плагина необходимо зайти в Файл->Шаблоны->Управление и загрузить файл шаблонов из архива с плагином.
Затем, OOoFBTools->Загрузка шаблона стилей в документ. F11
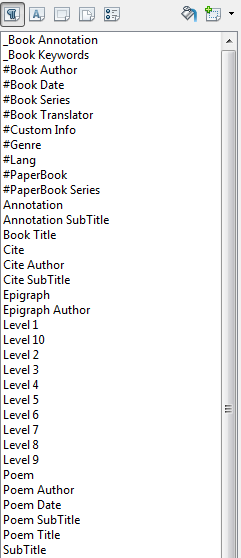
Получаем панель с основными стилями. Выделяем в тексте кусок, применяем подходящий стиль.
Стилями Livel* выделяются названия глав, разделов и прочего территориально-администра>тивного деления. Потом по этим данным будет создано оглавление.
Другие стили нужны для того, чтобы в книгочиталке (железной или программной) текст шел не сплошной волной, а отдельно были выделены вещи вроде эпиграфов, цитат и других полезных вещей.
Если скан хороший, то вся работа займет около полутора часов.
|
|
Категория: Новости |
Просмотров: 600 |
Добавил: andest
| Рейтинг: 0.0/0 |
|  |
 |  |
 |  |  |  |
|
| Поиск |
|
|
| Календарь |
|
|
| Архив записей |
|
|
|









